I Eat Tacos Every Valentine’s Day (CompTIA troubleshooting acronym, Part 2)
This is the CompTIA Troubleshooting Methodology
Identify the problem
Establish a theory of probable cause
Test the theory to determine the cause
Establish a plan of action to resolve the problem and identify potential effects
Implement the solution or escalate as necessary
Verify full system functionality and, if applicable, implement preventive measures
Document findings, actions, outcomes and lessons learned
At Per Scholas, I heard of a really great acronym for this CompTIA troubleshooting process: I Eat Tacos Every Valentine’s Day.
The A+ is updating now to the 1200 series, and I decided I was going to document my progress as our team gets to know the new exam from CompTIA.
1. Identify the Problem (I)
How do you find out about problems in life?
Perhaps it is a phone call. A help desk ticket. An email. A Slack message, and so on.
You cannot get upset if people approach you seeking help with problems, because that is what you would do if you were having a problem.
Your goal is to identify the root cause of an issue, which is not always apparent. TV dramas might make you wait like 50 minutes to get the answer, but in real life it might take much longer.
For example, a failed login attempt to the company’s Google workspace might seem to indicate that a user forgot their password, but the real issue could be that the network is down and the user cannot log into .
Just like medical doctors, IT professionals must be very careful about making the “correct diagnosis” to fix a machine, otherwise making more changes could make the problem even worse.
Specific substeps here may include:
Gathering information from logs and error messages
Questioning users (and taking notes)
Identifying symptoms
Identifying recent changes
Trying to safely replicate the problem
Process of elimination to narrow down the cause of the problem
2. Establish a Theory of Probable Cause (Eat)
Okay, so we have a “theory” as to what caused the problem, but we might not be entirely sure we are accurate.
This happens all the time: we have an answer, we aren’t sure it’s correct, but it is enough for us to begin the troubleshooting process. This might be:
Reading the vendor documentation
Reading documents made by staff members of your organization
Googling it
Searching Reddit
Like we discussed before, it's a process of elimination.
Big tech companies like Google, Cisco, Amazon Web Services, Microsoft and Apple maintain documentation and forums where troubleshooters exchange ideas, read about common causes, solutions and troubleshooting methods provided by others in IT, or regular people who solved a problem and were kind enough to upload their solutions to the Internet for you to find.
Question the obvious. Consider multiple approaches.

so many details!
”The devil is in the details.”
I have taught multiple CompTIA, Google Career Certificate, and AWS classes. I like the phrase "The devil is in the details" because it is an idiom meaning that seemingly simple things can become problematic due to hidden complexities or overlooked details. There’s even a Wikipedia article for it.
Learning how to use a new operating system, program a switch, deploy cloud resources, can be confusing. There are many details. It helps to take notes, and share the notes doc with your team, or on your personal website.
Your notes might be full of data you copied from websites, links to forums, vendor docs, intelligence you gathered from your family, friends, teammates, and so on.
3. Test the Theory to Determine the Cause (Tacos)
Steps one and two are about one thing.
Gathering information.
You don’t need to make changes to any machine until you are reasonably sure you have a solution you’re ready to deploy.
For issues and symptoms that are common, it’s a simple game: you investigate an error message or symptom, do a quick search, and apply a good fix from a search result.
But if you test the theory and find you were incorrect, you may need to start your research all over again.
Like a TV lawyer, you can check in with withnesses, dig deeper into the files, use Google, and so on, until you get another theory. I do this all the time in my current job at Per Scholas when I am investigating issues.
Sometimes the problem is in hardware like the CPU, the RAM, the SSD or HDD.

Or there could be problems with the operating system like iOS, or with applications such as Microsoft Word.
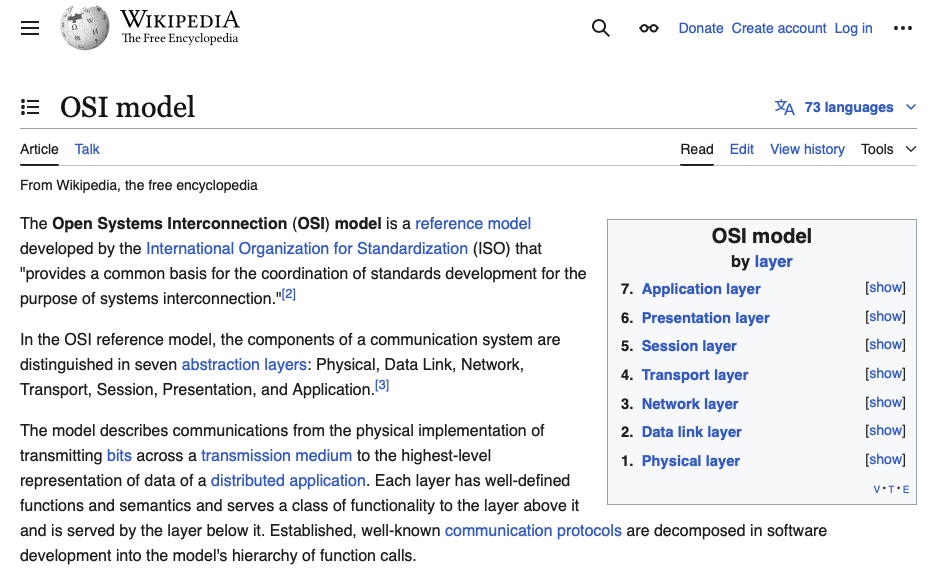
Troubleshooting network problems starts with the Open Systems Interconnection (OSI) model.
You can start by verifying the system's IP address configuration. Then the status of routers or switches.
From there you can verify net services like DNS, DHCP, or firewalls. CompTIA has a blog about using Wireshark that can be helpful as well.
4. Establish a Plan of Action and Implement the Solution (Every)
If you are confident you found the root issue, the next step is to create your action plan and TAKE ACTION!
Remember to factor in downtime. Reboots could take a while. Downloading software, drivers or entire operating systems can takes time. It’s also probably safer to test any modifications in a sandbox before deploying the fix into production.
Did you back up the data? Losing your data and not having a backup in an offsite location can be catastrophic for a business or an individual.
Do your teammates approve and support this idea? I know, it can be embarrassing to talk about problems you are facing. There are many TV shows out there as well where someone jumps ahead with a plan without getting approval or support from their teammates, and it doesn’t always work out well. It’s better just to talk about it and take notes on the discussion.
Once this is done, and you have a rollback plan, you can finally take action. A rollback plan matters because if this fix doesn’t fix, hopefully you can roll back to where you began.
5. Verify Full System Functionality and Implement Preventive Measures (Valentine’s)
Follow up with your “patients.” After you fix a machine, have the users that rely on the system test it, and confirm with you that it works in person or in writing. They are the ones that really know how the system is supposed to act and they can ensure that it works properly.
It’s also good to educate the user to make sure this error can be prevented in the future, or configure the machine so that the error doesn’t happen again.
6. Document Findings (Day)
One of my teammates at work recently called me “Mr. Notes.” But ever since I got into management, documentation has been so necessary. Keeping a personal diary, analog and digital, has helped me personally and professionally. At work, I basically maintain this practice.
I’ve had a website for a while as well. I figured it would also be good to document some of the steps, changes, updates, theories and research I’ve gathered over my working lifetime.
If you have learned a lot of things, it would be a disservice not to share some lessons you learned.
A part of me feels this website of blog posts, perhaps YouTube videos in the future, could all be useful to the people on the Internet, perhaps a future version of myself.
Problems have a way of coming up for us. There’s always going to be a market on documentation that can help us overcome the problems that come up, in life or work.
One of the best questions is “what have you tried so far"?” You can save yourself, your teammates, or your technical support a lot of time by mentioning all the things you already tried, and do not have to try again. Rollback plans are also easier to deploy, because you can reverse the changes and discussions you noted through text, screenshots, YouTube videos, reddit threads, Wikipedia articles, AWS whitepapers, Google searches, and so on.